
Nowadays, search engines are the go-to tool when internet users want to find new information on the internet. Having your website rank highly in a search engine is one of, if not the best way to increase your visitor numbers. These search engines use bots called web crawlers (a.k.a. web spiders) to scour your sites for links and content. These crawlers then index your site’s content which allows your pages to show up on the search engines’ SERP (i.e. Search Engine Result Page) pages.

A robots.txt file, also known as Robots Exclusion Protocol, is a text file which is placed into the root of the domain. It instructs the spiders which pages they are allowed to crawl and which ones not to. Originally, robots.txt was used in order to help the spiders find all of the site’s pages, especially if the site didn’t have a good internal linking system. Since their introduction however, these bots have gotten very good at finding all the pages in a site and indexing them, so why is robots.txt file useful now?
With the ever-increasing popularity of the internet, websites are only growing in size and new webpages are added to them daily. Once a search spider arrives at a website, it has a predetermined “allowance” of how many pages it will crawl, which is referred to as the crawl budget. Blocking parts of your site from the web crawlers will allow you to use the crawl budget for your most valuable pages. It could also be beneficial for the site to have their more problematic or non-SEO-optimized pages hidden from the crawlers while the SEO-cleanup is being done.

There is one scenario where blocking spiders is crucial to not depleting the crawl budget. In cases where the site uses a lot of query string parameters to filter and sort through content, having as little as 10 different parameters that can be used in any combination, could create thousands of possible URL. Blocking all query parameters from being crawled is essential to keeping your crawl budget from diminishing before the spiders can reach your main pages. Here’s a line of code that blocks crawlers from every URL containing a query string on your site:
Disallow: /*?*
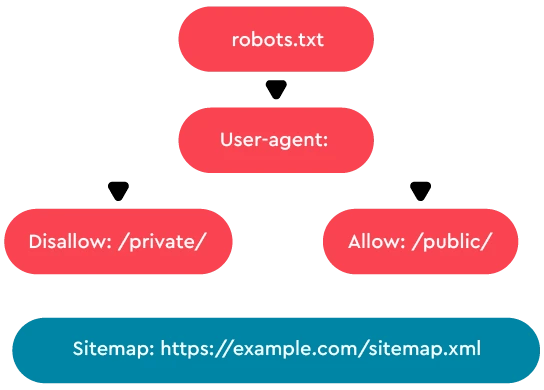
So, how does one go about making a robot file? Generally, it consists of blocks of directives, each one beginning with User-agent. This is the name of the specific bot it addresses (e.g. Googlebot is Google’s spider). It is then followed by Disallow which states which directories/pages/files the previously defined bot should not visit. You can have one or more of these lines and leaving it blank will give the spider access to all parts of your site. The syntax is very strict as it has to be computer readable.
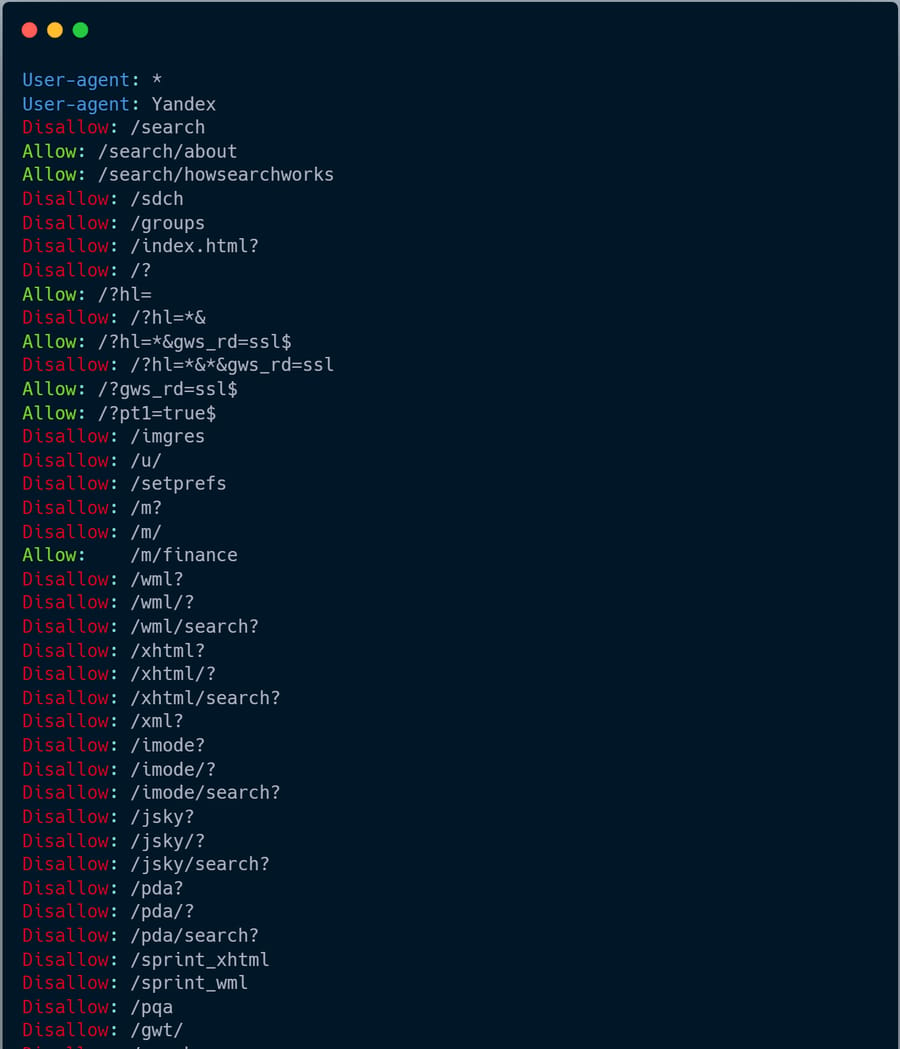
Here are some examples of robots.txt files and what they mean:
User-agent: *
Disallow: /
These two lines block all bots from crawling your entire site.
User-agent: Googlebot
Disallow: /confidential
This will stop Google’s spider from crawling the /confidential directory.
|
Directive |
Description |
Example |
Use Case |
|
User-agent |
Specifies the web crawler |
User-agent: Googlebot |
Target Googlebot specifically |
|
Disallow |
Blocks access to specified URL path |
Disallow: /admin/ |
Prevent crawlers from admin pages |
|
Allow |
Allows access even if parent disallow |
Allow: /public/ |
Allow access to specific subfolder |
|
Sitemap |
URL of the sitemap file |
Sitemap: /sitemap.xml |
Help crawlers find all URLs faster |
Keep in mind that the robots.txt file is case sensitive and that specific search engines can have some certain directives that others do not accept. For example, Google uses the Allow directive which does the opposite of Disallow.
