
With 2025 witnessing a rise in connected devices and applications that require real-time functioning, the need has become paramount for low-latency, efficient data processing, which, in turn, has made fog and edge computing significant in contemporary IT architecture. Fog computing vs edge computing brings computation close to where data is generated to keep away from computing in big centralized cloud systems; however, they vary in role, structure, architecture, and suggested use cases.
As companies attempt to deal with the explosion of IoT data, autonomous systems, and bandwidth-hungry services, becoming familiar with the difference between fog and edge computing grows even more critical in designing scalable, responsive, and secure digital infrastructures.
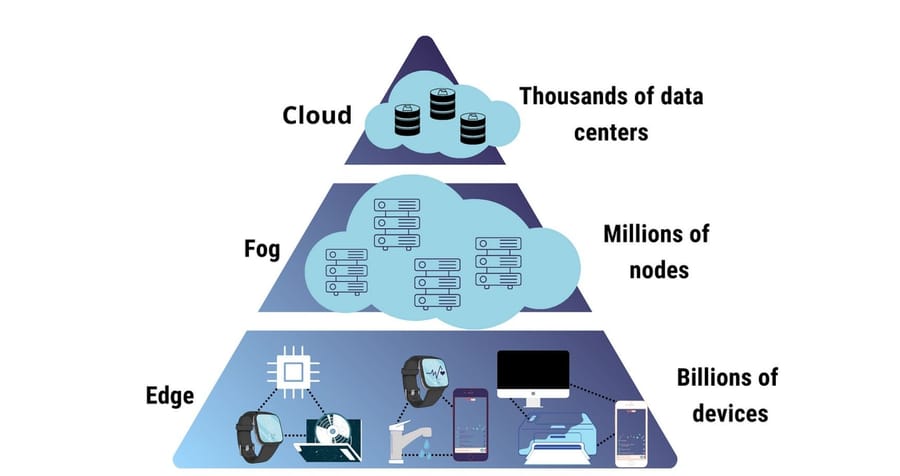
What Is Edge Computing?
Edge computing is a modular type of distributed computing that brings data processing nearer to the physical location where data is generated—sometimes right on the devices themselves, sometimes on local servers close to them. Data may be sent to a centralized cloud for analysis, or, depending on the situation, edge computing allows for data to be processed at or near the source end to create the required real-time decisions. This is particularly important for low-latency applications like autonomous vehicles, industrial automation, or augmented reality systems.
Related Article: What is Cloud Computing?

Consider a smart thermostat, which does not completely abide by the notion of a cloud-based IoT device to decide when to change temperature settings. The smart thermostat can instead compute environmental data locally and make decisions immediately. That is a benefit of having real-time responsiveness from an edge computing concept. In addition, edge computing gives you privacy, saves bandwidth, and maintains functionality during network outages. However, some drawbacks include difficult large-scale management, restricted processing power compared with the cloud, and the exigency of securing a plethora of endpoints to block any security lapses appearing within the distributed network.
Related Article: Edge Computing vs Cloud Computing
What Is Fog Computing? Fog computing definition
Fog computing is supposed to extend cloud computing and decentralize processing by including an intermediate layer between the cloud and edge devices. This term, fog, is coined by Cisco, and the meaning conveyed is this intermediate layer, bringing computing, storage, and networking services closer to where the data originates, but not directly on the device itself.
They could be maybe routers or gateways or servers placed in the local network, which have some analytics, control functions, etc, without having to just push all the raw data up to the cloud. This architecture comes into play when the local edge devices are resource-constrained for heavy processing, but solutions from the cloud would cause considerable latency.

An instance of such a system is an innovative traffic lighting system. Sensors in city areas gather traffic data and transmit it to the fog nodes close by to regulate light patterns dynamically. At the same time, the summarized data is sent to the cloud for long-term analytics and infrastructure planning. Fog computing is expected to bring down latency and reduce bandwidth consumption and dependency on the Internet. Its advantages include scalability, filtration of unnecessary data before sending to the cloud, and system efficiency enhancements.
Fog computing vs edge computing: Key Differences
Although fog computing and edge computing are closely related, they serve different purposes in a distributed architecture. The key difference lies in how close each technology is to the data source and where processing occurs. Understanding their distinctions is essential for building efficient, secure, and scalable systems, especially in latency-sensitive applications like autonomous vehicles, smart cities, and industrial IoT.
|
Criteria |
Edge Computing |
Fog Computing |
|
Proximity to Device |
Very close—often on the device itself or embedded in local hardware |
One step above the edge—located between the device and the cloud (e.g., gateway or router) |
|
Processing Location |
Directly on or near the device |
On intermediate nodes such as local servers or gateways |
|
Latency |
Ultra-low latency due to immediate local processing |
Low latency, but slightly higher than edge due to an extra network hop |
|
Bandwidth Usage |
Reduces bandwidth by minimizing cloud communication |
Filters and summarizes data before sending to the cloud, saving bandwidth |
|
Scalability |
Less scalable individually; requires many devices to scale |
More scalable through centralized fog nodes serving multiple edge devices |
|
Control & Security |
Greater control at the device level; may require securing many endpoints |
Centralized control over multiple edge nodes; easier to manage policies |
|
Use Case Example |
Real-time AR/VR, autonomous vehicles |
Smart city traffic systems, industrial automation |
|
Real-World Analogy |
Like a personal assistant handling tasks on your phone |
Like a neighborhood manager coordinating tasks for several assistants nearby |
Fog computing vs edge computing
Real-World Use Cases
In real-world use cases, fog computing proves extremely useful wherever distributed coordination or intermediate processing is expected, coupled with proper cloud interfacing. In smart cities, the fog nodes process data from cameras, traffic lights, and public transport to make local decisions, like dimming the brightness of street lamps or diverting traffic; heavy analytics are then forwarded to the cloud. In industrial automation, predictive maintenance uses fog to process equipment data near the factory floor, reducing downtime.
In route optimization, local object detection, and swarm coordination without relying on a central data center, drones adopt the fog architecture to ensure real-time responsiveness even when bandwidth is scarce or the area is remote.
If any sectors were to get maxed out for edge, it would be least latency and on-device-intelligence scenarios. AR/VR requires edge signaling for rendering frames and processing interactions to prevent actual motion lag. Self-driving cars are another edge use case where a far-away data center cannot delay instant decisions like obstruction detection or lane changes. Remote environmental sensors with edge devices filter and summarize readings to preserve bandwidth and battery life. In 2025, emerging technologies like edge AI, digital twins, and collaborative robotics drive demand for hybrid fog–edge architectures that balance local autonomy with broader system insight, highlighting the need to match deployment strategies with latency sensitivity, bandwidth constraints, and real-time requirements.
Reducing the latency is the goal of the computing approach
When to Use Edge, Fog, or Both
Choosing between edge computing, fog computing, or a hybrid approach depends on specific deployment needs such as latency tolerance, infrastructure scale, security requirements, and available resources. Here’s a scenario-based guide to help determine the right architecture for your use case:
- Edge computing examples:
- You need ultra-low latency and real-time decision-making at the device level (e.g., autonomous vehicles, AR/VR).
- Devices must operate autonomously, even without constant connectivity to the cloud.
- You want to reduce cloud dependence and enhance data privacy by keeping data processing fully local.
- The workload is lightweight enough to be handled by on-device or near-device resources.
- Use cases of fog computing:
- You require localized processing across multiple devices with limited on-device resources (e.g., factory floors, smart grids).
- The system must aggregate, filter, and analyze data before sending it to the cloud for long-term storage or deeper analytics.
- A moderate latency is acceptable, but bandwidth efficiency and scalability are priorities.
- You need centralized control over edge nodes, simplifying security and policy enforcement.
- Use Both Edge and Fog When:
- You're deploying a large-scale IoT network with both real-time local needs and system-wide intelligence (e.g., smart cities, logistics).
- You want hierarchical processing—instant actions at the edge and contextual decision-making at fog nodes.
- Data must flow across multiple layers, enabling adaptive processing based on urgency, data type, or source.
- Your system involves AI inference at the edge, with ongoing training and coordination handled by fog nodes.
Fog + Edge in 2025
The combination of fog and edge computing in 2025 is evolving into a hybrid model that takes on the best of each architecture. With the widespread adoption of 5G and distributed cloud infrastructures, these emerging systems facilitate seamless coordination between edge devices and multiple fog nodes, transforming them into intelligent networks capable of instant decision-making with wholesome contextual understanding.
In synergy with areas such as healthcare, manufacturing, and autonomous transport, it supports predictive data processing in which AI models view trends locally and pass on refined warnings. Inference at the edge supported by fog-based coordination delivers real-time responsiveness, placing these fog-edge hybrids at the backbone for intelligent and adaptive next-generation systems.
Conclusions
As enterprise IoT trends flow, it is essential to know the key differences between Fog computing vs edge computing to answer the call for responsive, scalable, and secure systems. On the other hand, edge computing works on data right at or near the device for an instant decision. In contrast, fog computing becomes an intermediary for data aggregation, filtering, and contextualization near the source but with a wider scope. The year 2025 welcomes these complementary offerings, especially with the advent of 5G, AI inferencing, and latency-critical applications.
